A few years back we built Applied Materials corporate website. This website was localized to 5 different languages: English, Japanese, Korean, Chinese (both simplified and traditional). Non-English pages were set to default to English if a translation didn’t exist for the selected language.
Last week our client asked us if we could put together a report indicating the amount of text pending to be translated for each of the languages supported by the website.
Basically, if the user selected Japanese, the client wanted to know how many pages were still showing English content. Furthermore, the client would be very pleased if they knew how much of each page was translated (none, half, all?).
Some pages were “completely” translated:
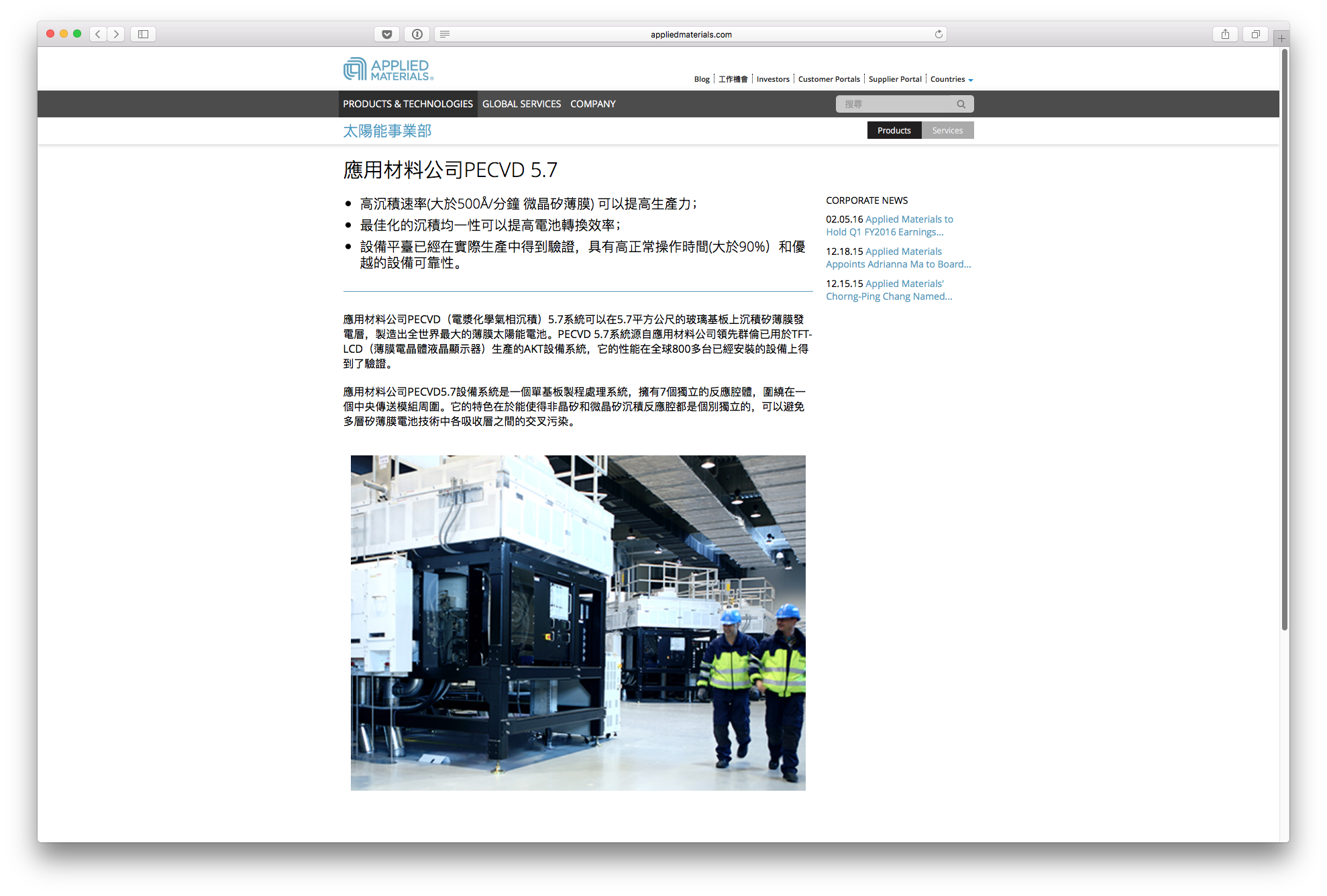 A “fully” translated product page
A “fully” translated product page
Some pages were not translated at all:
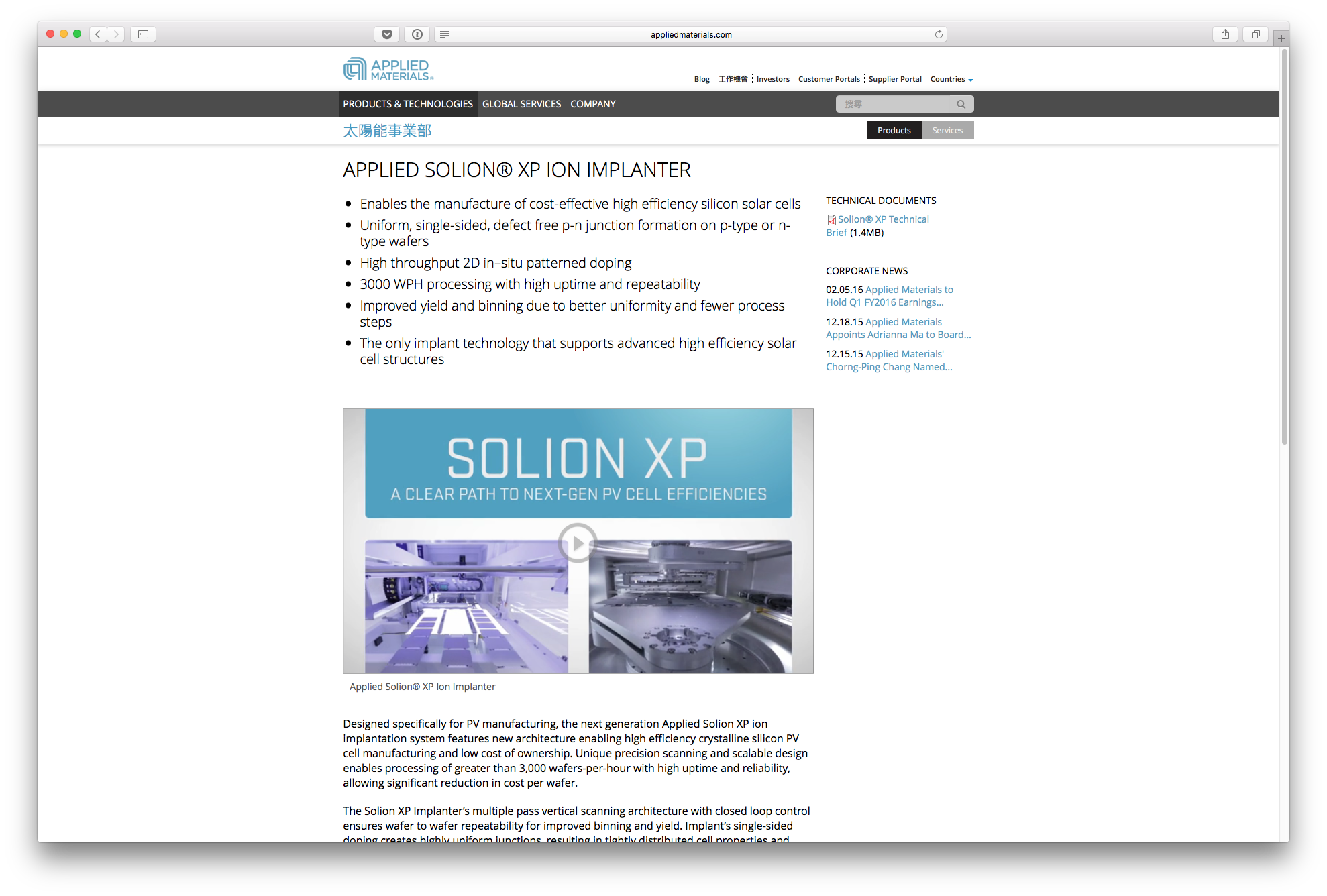 A non-translated product page
A non-translated product page
Other pages had a mix of translated content and non-translated English content:
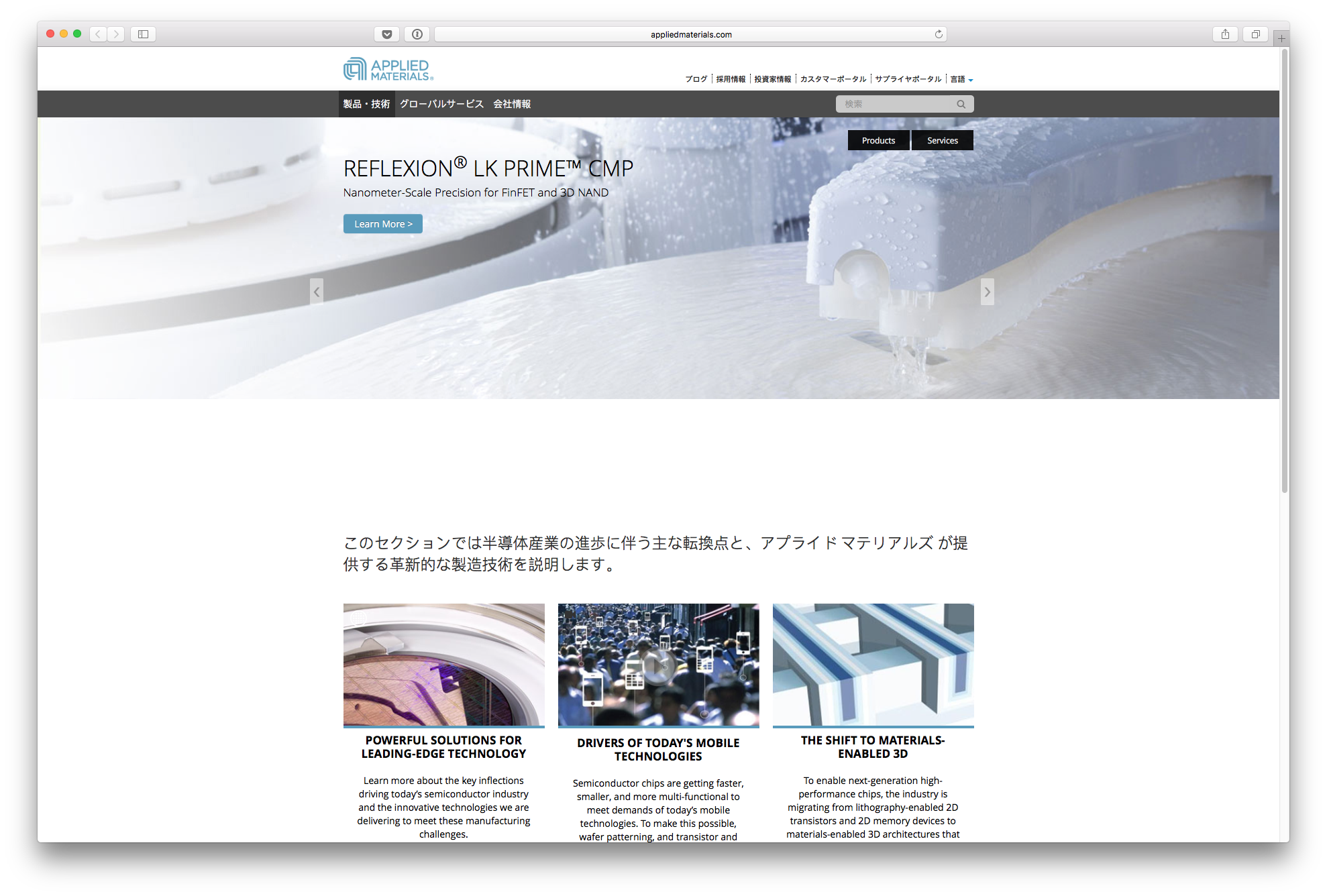 Half translated page
Half translated page
Solving the Problem
Since the website is pretty large, I thought it would be nice to write a crawler and analyze the text extracted from the website to detect the languages using a language detection algorithm.
The job could be split in three major tasks:
- Crawl (to navigate each page of the site)
- Text Extraction (to get relevant copy from the HTML)
- Language Detection (to provide the results we needed)
Crawl
I wanted the crawler to be fast and to focus first on the top level pages. To make it fast, I wrote a multi-threaded application to process many pages in parallel. To focus on the top level pages, I used a Minimum Priority Queue with the priority based on the length of the url.
Worker Threads
Used to GCD and NSOperationQueue, it had been a while since I last wrote a program with a thread pool of worker threads. I wondered about using NSThread but I decided to give dispatch_group a shot.
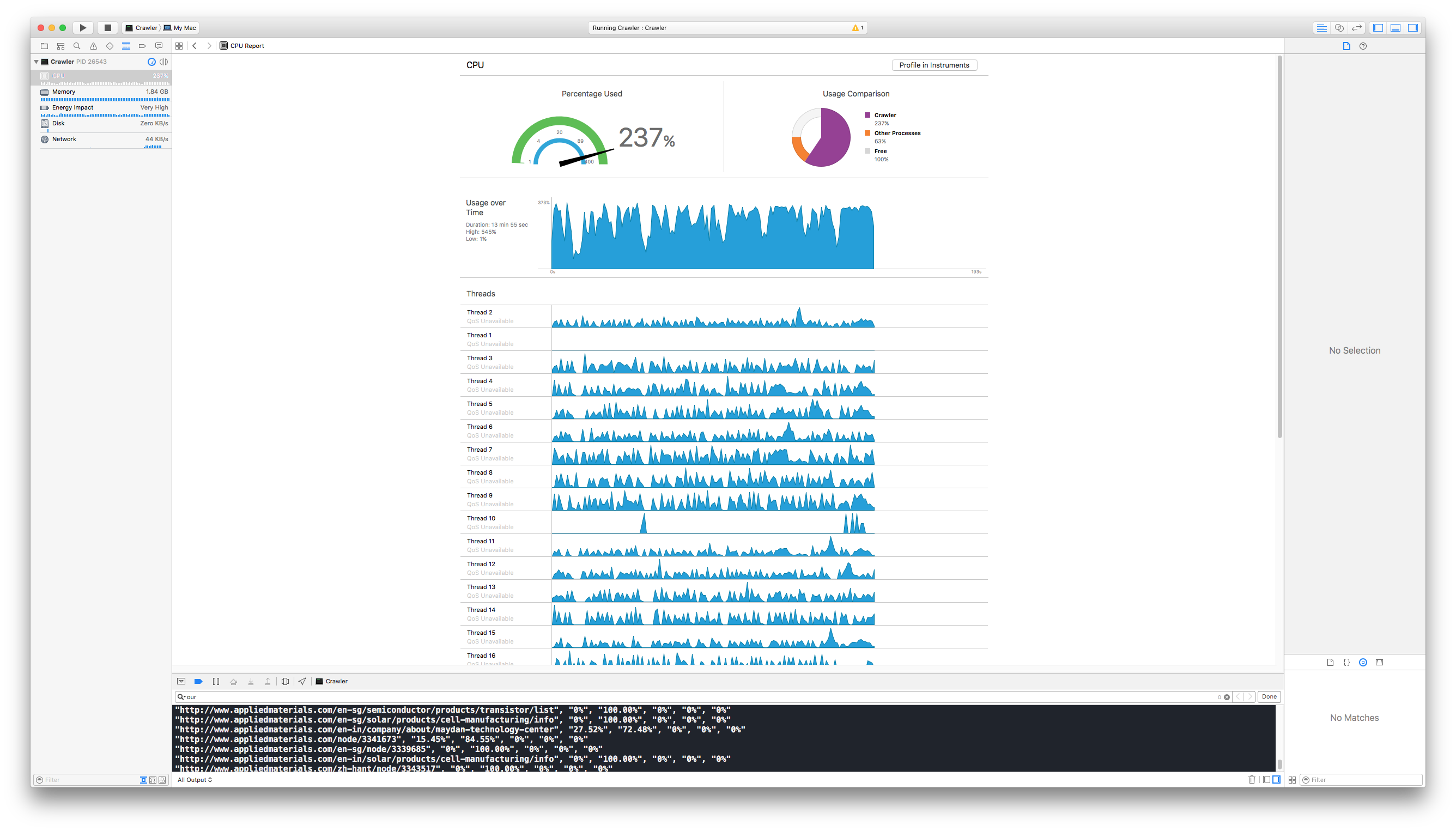
The workers wait for a job until they get one from the queue. The process stops when the queue is completely empty and no worker is actively processing a page. In my tests, it seems that 10 to 20 threads worked best.
Xcode CPU view shows active worker threads
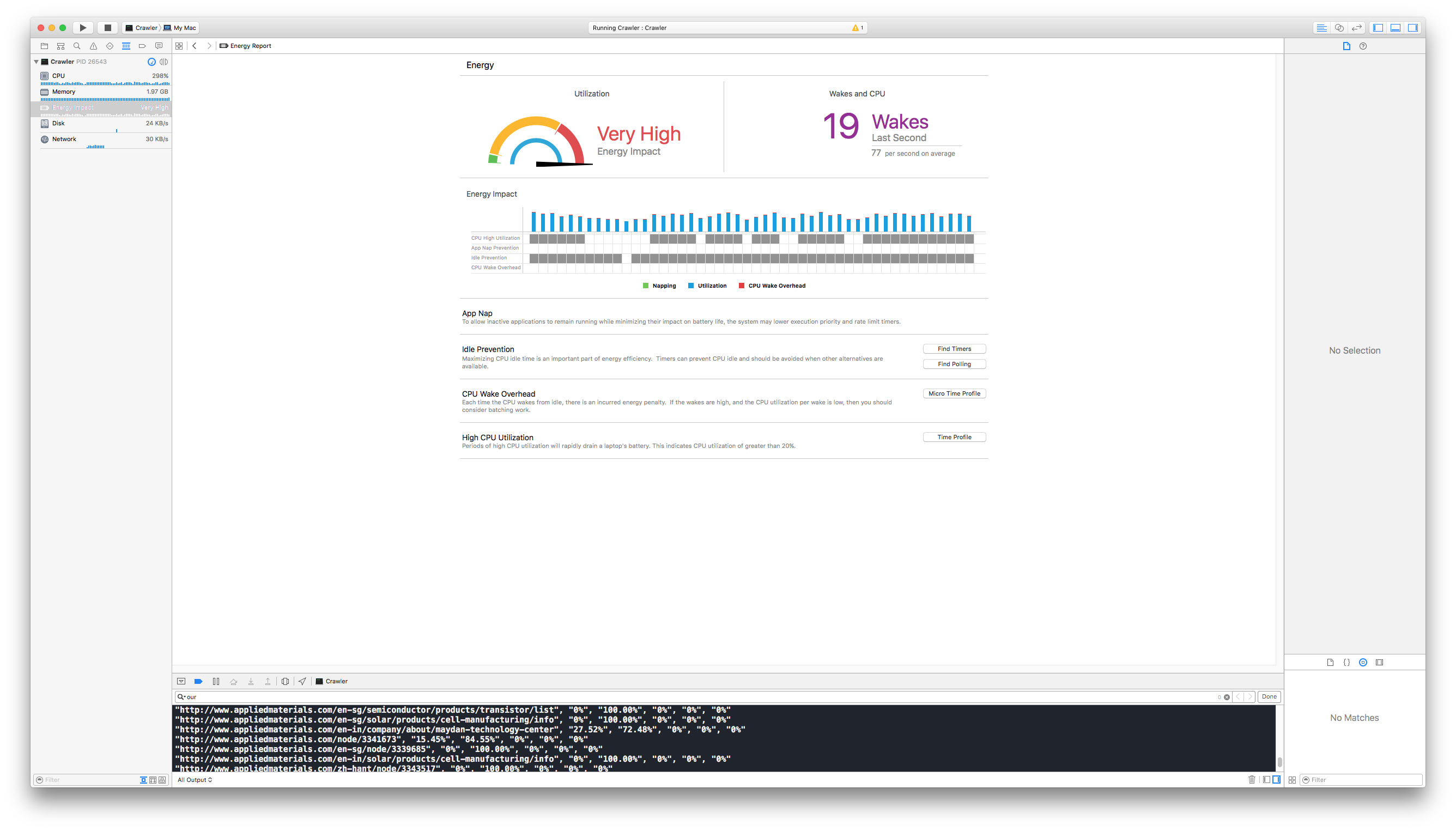 Squeezing all the juice from my laptop
Squeezing all the juice from my laptop
Priority Queue
In an attempt to do a breadth-first crawl, I used a Minimum Priority Queue with the priority based on the length of the url. Shorter urls would then be processed first, while longer urls will be left for later processing.
I wrote a concurrent-ready wrapper for the Priority Queue. Using NSLock it will guarantee safe access to add and remove items to and from the queue. This queue will also keep track of previously processed urls, to avoid adding duplicates.
Interestingly, Swift defer can remove the lock after returning the result. I found that pretty sweet (see removeJob() and isEmpty() methods below).
class CrawlQueue {
let queueLock = NSLock()
var queue: PriorityQueue<CrawlJob>
var uniqueURLs: [String]
init() {
queue = PriorityQueue<CrawlJob>(order: .Min)
uniqueURLs = []
}
func addJob(job: CrawlJob) {
queueLock.lock()
if uniqueURLs.contains(job.url.absoluteString) == false {
uniqueURLs.append(job.url.absoluteString)
queue.add(job)
}
queueLock.unlock()
}
func removeJob() -> CrawlJob? {
queueLock.lock()
defer { queueLock.unlock() }
return queue.remove()
}
func isEmpty() -> Bool {
queueLock.lock()
defer { queueLock.unlock() }
return queue.isEmpty()
}
}
Text Extraction
HTML Tags
After retrieving the HTML content of a page, we had to extract the text. Instead of checking the entire HTML, I focused on <h1>, <h2>, <h3>, <h4> and, most importantly, <p> tags. I considered checking also for links (<a> tags) but finally decided to not include them as most of them were related to navigation.
Regular Expressions
While HTML cannot be parsed with regular expressions (thanks for the reminder, Vincent), I found that for the job at hand, regular expressions were good enough (thank you for the assistance, Kevin Strong).
When extracting text from the HTML, I noticed that extracting substrings from a NSString was much, much, faster than doing it from a Swift String (maybe because of the NSRange to Range conversion).
NSString version:
func matchesForRegexInText(regex: String, text: String) -> [String] {
do {
let regex = try NSRegularExpression(pattern: regex, options: [.CaseInsensitive])
let range = NSMakeRange(0, text.characters.count)
let results = regex.matchesInString(text, options: [], range: range)
let nsString = text as NSString
let urls: [String] = results.map { result in
return nsString.substringWithRange(result.rangeAtIndex(1))
}
return urls
} catch let error as NSError {
print("invalid regex: \(error.localizedDescription)")
return []
}
}
String version (much slower):
func matchesForRegexInText(regex: String, text: String) -> [String] {
do {
let regex = try NSRegularExpression(pattern: regex, options: [.CaseInsensitive])
let range = NSMakeRange(0, text.characters.count)
let results = regex.matchesInString(text, options: [], range: range)
let urls: [String] = results.map { result in
let start = text.startIndex.advancedBy(result.rangeAtIndex(1).location)
let end = start.advancedBy(result.rangeAtIndex(1).length)
return text.substringWithRange(Range<String.Index>(start: start, end: end))
}
return urls
} catch let error as NSError {
print("invalid regex: \(error.localizedDescription)")
return []
}
}
Link extraction:
matchesForRegexInText("href=\"([^\"]*?)\"", text: html)
Text block extraction:
matchesForRegexInText("<\($0).*?>(.*?)</\($0)>", text: html)
Language Detection
Naive Bayes Classifier
I looked online for different language detection libraries. I found this Parsimmon Naive Bayes Classifier written by Ayaka Nonaka and I was very pleased with it.
 Parsimmon by Ayaka Nonaka
Parsimmon by Ayaka Nonaka
Naive Bayes Classifiers work not by detecting the actual language of a piece of text, but instead by matching it against some text samples previously provided to train the classifier.
let classifier = NaiveBayesClassifier()
classifier.trainWithText("Investor Relations", category: "en")
classifier.trainWithText("Emerging Technologies and Products", category: "en")
classifier.trainWithText("製品・技術", category: "jp")
classifier.trainWithText("グローバルサービス", category: "jp")
classifier.classify("Investor") // "en"
classifier.classify("技術") // "jp"
I had to train the classifier with many more text samples, but at the end it turned out to be pretty accurate.
Detecting Many Languages vs. Differentiating Between Two
At first I tried crawling all pages for all languages and have the classifier discern among all 5 languages. The results were not very accurate and it seemed as if it was hard to tell apart the four asian languages.
To increase the accuracy, I ran the crawler separately, focusing only on one language at a time (urls starting with /ja for example) and detecting if the blocks of text were english or Japanese.
The results were so accurate I was thrilled.
Generating Output
For the output I went for a CSV format, printed in the process output as the workers processed every page. The output could be piped to a file from the terminal or copied and pasted from the Xcode console into a text file.
From there, it will take no effort to import the CSV file into Google Docs.
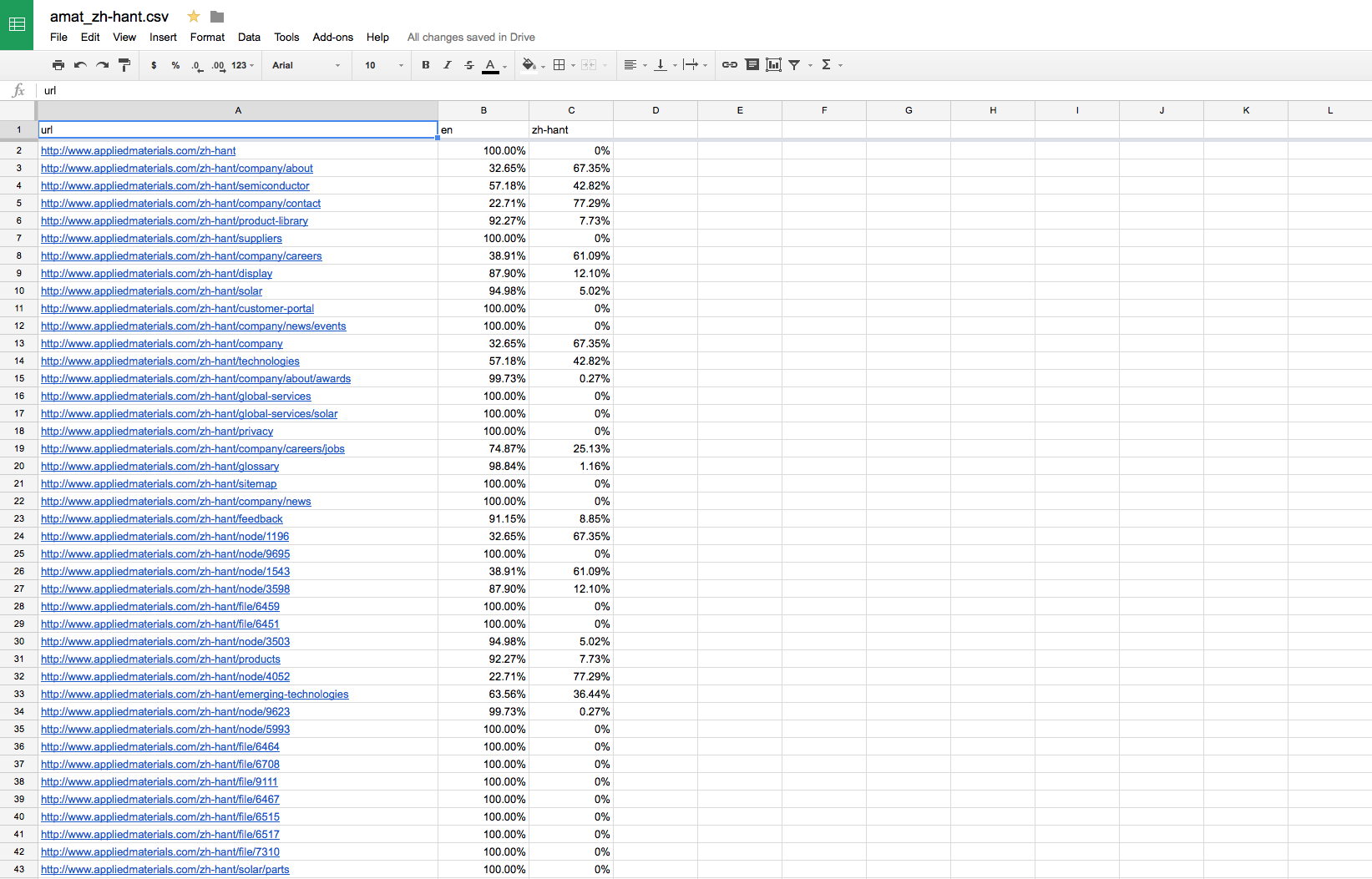 Output Report in Google Docs
Output Report in Google Docs
Conclusion
Hope you enjoyed the reading as much as I enjoyed writing this crawler :)